Improving Time-to-Model: Fast, Standard Feature Transforms
TL;DR
Business stakeholders and data practitioners often share a pain point: the cost of reaching a baseline predictive model, even with analyst-friendly data in hand. That’s partly because, analyst-friendly data likely need transformed to model-ready data. Transformations encapsulate within a feature transform workflow/pipeline. This high-level pipeline creation can require major effort.
To reduce typical time and complexity costs of workflow creation, I propose a standardized procedure, which draws on software engineering first principles. The solution de-couples standard operations from project-specific configuration. That configuration should be understandable to any motivated reader, including C-Suite leaders.
After writing a few easy-to-read configuration files, get model-ready data with just one command line statement:
python -m src.features.mainWith this system, I accelerate my own modeling projects. This system was inspired from work on a product concept for baseball analytics and trading card valuation.
I welcome your feedback on the implementation’s current state.
Problem: Cost of Baseline Model, Even with Analyst-Friendly Data
Business stakeholders and data practitioners often share a pain point: the cost of reaching a baseline predictive model, even with analyst-friendly data in hand. Why? A data representation may be analyst-friendly but not model-ready. So the analyst-friendly data need transformed to explicit model features. Those transformations encapsulate within a feature transform workflow/pipeline. This high-level pipeline creation can require major effort.
The pipeline creation cost breaks into addressable pieces.
Time Cost
We decrease project time-to-value with more reuse of existing code. There’s significant opportunity for more reuse of feature transform pipeline code, especially project-to-project. Code re-writes are common between projects, or even within-project, depending on gaps between R&D and software engineers. But there’s a better way.
Complexity (Technical Debt) Cost
Code complexity slows progress. Code complexity may be due to system design challenges: components lack orthogonal, modular nature. When a code workflow becomes hard to mentally model, it’s very hard to:
- Describe, debug current state
- Deliver improvements with confidence
- Inspire trust in system behavior and results
There’s significant opportunity to de-couple (a) standard transforms workflow from (b) project-specific configuration. Imagine a feature transform pipeline described with key-value pairs, and controlled from the command line.
To Solve, Let’s Learn From Software Engineers
To compose a standardized feature transform pipeline, which reduces time and complexity costs (especially project-to-project), software engineering first principles help.
The overall pipeline should combine small, loosely-coupled units. Then, the system is easier to follow at macro- and micro- levels. A popular data analysis system schematic carves out components that are modular and orthogonal:
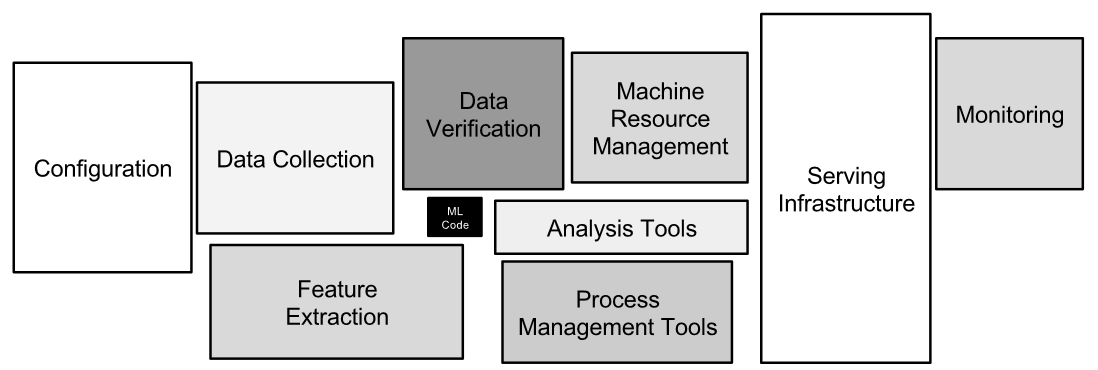 SOURCE: Hidden Technical Debt in Machine Learning Systems
SOURCE: Hidden Technical Debt in Machine Learning Systems
With regard to de-coupling of configuration and operations. Cutting-edge open source software embraces low-visual noise interfaces for configuration:
pydantic, creator of a crisp data validation interface, was recently backed by Sequoiadbt, creator of standardized patterns and tooling for data transformation
Solution Runs with One Command
With a pipeline configuration declared, get model-ready data with just one command line statement:
python -m src.features.mainTo be sure, several implementation scripts allow this to work. I welcome your feedback on the implementation’s current state.
So, how do we declare the configuration?
Solution Includes Easy-to-Read Workflow Configuration
Ideally, many projects should leverage standard transform pipeline code, with each just updating a configuration. That configuration should be understandable to any motivated reader, including C-Suite leaders.
An overall workflow configuration subdivides, into configurations of (a) source data and (b) feature transforms.
Data Sample Configuration
When we analysts receive the question, “what data were used in this analysis?” – one configuration file should quickly confirm. After all, data are real, while models are abstractions. A derived feature transform pipeline depends critically upon data sample details:
- On this process run, will we re-derive/re-train the pipeline?
- From what storage source do we extract data?
- In a database, which tables record inputs (X) & outcomes (Y)?
- What filters subset data which trained this pipeline? Or, what filters subset a new test run’s data?
- A descriptive title/tag aids understanding
- What outcome do we seek to predict? How should we treat its missing values?
- What columns constitute data attributes: not-for-modeling subject identifiers, useful in exploratory analysis?
To centrally capture those details, we use a fun-to-read file of key-value pairs. An example follows, from baseball card valuation modeling:
is_training_run: true
source:
storage_type: database
X: seed.trading_card_transactions_features
Y: seed.trading_card_transactions_value
filters:
title: post_202304
time_field: id
time_min: 918
time_max: 2000
filters_train:
title: thru_202304
time_field: id
time_min: 0
time_max: 917
outcome_definition:
title: unit_price
do_drop_na: true
fillna_value: 0
dataset_attributes:
- id
- nameFeature Transforms Configuration
When we analysts ask the question, “what transformation steps yield my model-ready data?” – one configuration file should quickly confirm. There’s a better way than each time combing through scripts. Moreover, an analyst adds high value by determining smart data transformations. Operations code is more a liability than an asset.
Feature transforms may be sufficiently configured in one file:
- Uniquely name the workflow. (Arbitrarily many workflows could transform a dataset.)
- Declare transform functions (“transformers”) with preset arguments.
- Declare model features. For each,
- What’s the data type?
- Which transforms apply?
Another example from baseball card valuation modeling:
title: narrow
transformers:
impute_numeric:
strategy: median
add_indicator: true
impute_numeric_zero:
strategy: constant
fill_value: 0
add_indicator: false
impute_numeric_flag:
strategy: most_frequent
add_indicator: true
features:
print_year:
dtype: float
transforms:
impute_numeric:
is_base:
dtype: float
transforms:
impute_numeric_flag:
is_serial_numbered:
dtype: float
transforms:
impute_numeric_flag:
serial_numbered_to:
dtype: float
transforms:
impute_numeric:
is_rookie_card:
dtype: float
transforms:
impute_numeric_flag:
is_autographed:
dtype: float
transforms:
impute_numeric_flag: